Apriel-H1
Why efficiency-optimized reasoning matters now
Torsten Scholak — Lead Research Scientist
SLAM Lab — ServiceNow
November 2025
Apriel-H1
What You Get
Today we release Apriel-H1:
- Hybrid reasoner distilled from Apriel-15B
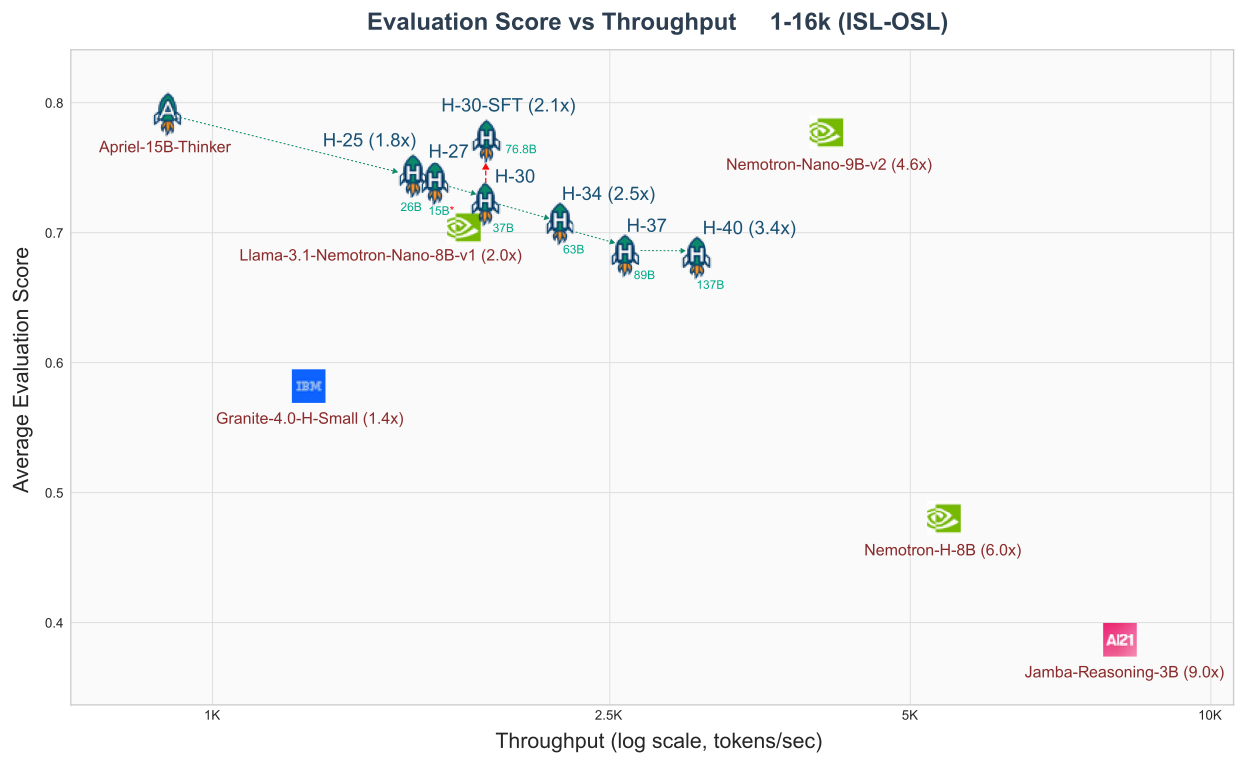
- ~2× throughput in vLLM with minimal quality deltas
- Runs today in vLLM
Proof It Works
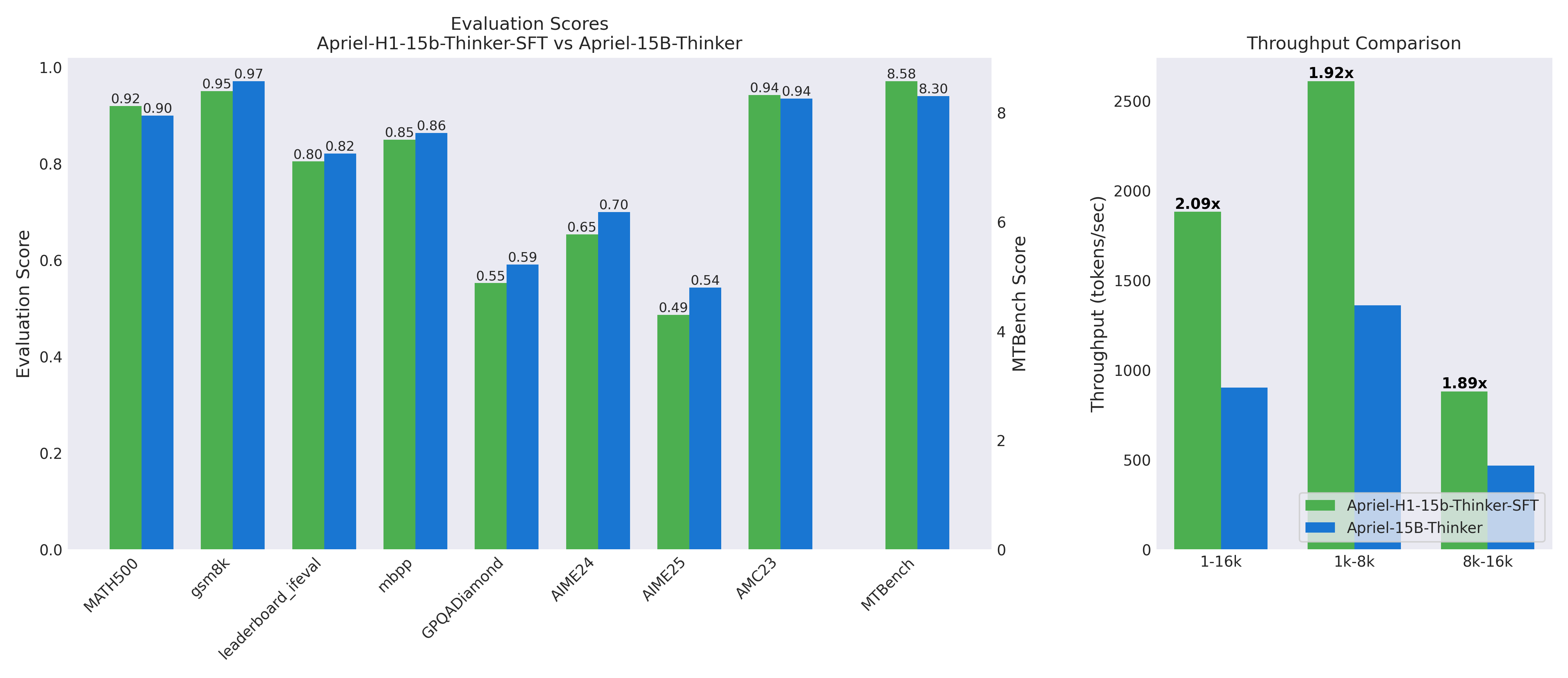
| Metric | Apriel 15B | Apriel-H1 30 | Δ |
|---|---|---|---|
| Throughput (vLLM) | 1× | ~2× | +2× |
| MATH500 | 90 | 92 | +2 |
| GSM8k | 97 | 95 | −2 |
| AIME'24 | 70 | 65 | −5 |
| GPQA-D | 59 | 55 | −4 |
| MBPP | 86 | 85 | −1 |
| MT-Bench | 8.30 | 8.58 | +0.28 |
Evaluation Results
How Apriel-H1 Works
Architecture — H1-30
- Start: Apriel-15B teacher (50 FA layers)
- Replace least-critical FA layers with Mamba (no KV cache, linear time)
- Keep 20 FA layers to preserve global patterns
Distillation — 3 steps
- Score layer importance (LOO perf drop + MMR distill loss)
- Swap low-importance FA → Mamba (MIL-style init from attention)
- Stage & gate: H1-25 → H1-27 → H1-30 (… H1-34/37/40) with reverse-KL; ship at best quality/throughput trade
Teacher (50L): [FA][FA][FA][FA][FA][FA][FA][FA][FA][FA] ...
H1-30: [FA][FA][FA][M ][FA][M ][M ][M ][M ][FA] ...
^ ^ ^ ^
"keep" "convert" "convert" "keep"Eval Score vs Throughput